Hvordan lese en forskningsartikkel
29-11-2020 (Last ned)
Forord
Stian publiserte tidligere en omfattende artikkel angående forskning, som spesielt omhandlet eksperimentell metode. Denne artikkelen vil være praktisk rettet mot de respektive delene av en artikkel, og hva du bør se etter. De fleste artiklene er bygget opp etter en IMRaD struktur. Akronymet IMRaD står for introduction, methods, results and discussion. På norsk blir det introduksjon, metode, resultat og diskusjon. Hver av disse kapitlene har forskjellige formål og bygger på hverandre. Vi skal skrape overflaten på de respektive delene og se på hva du bør se etter når du leser artikler.
-
1. En studie forteller ikke hele sannheten, men flere studier kan gjøre at du kommer deg nærmere sannheten.
- 2. Abstraktet forteller deg ikke alt, men gir deg et raskt overblikk over hva studien handler om.
- 3. Konklusjoner er tentative, og feltet beveger seg videre. Dette bygger litt på punkt 1, men en studie gir deg bare en brikke av puslespillet. Puslespillet blir også oppdatert til enhver tid.
Introduksjon
I denne delen av artikkelen legger forfatterne frem et teoretisk bakteppe for det de har undersøkt i artikkelen. Her gjennomgår de tidligere forskning. Dette i kombinasjon med annen relevant litteratur danner grunnlag for forskningsspørsmålet (problemstillingen) og hypotesene de skal undersøke. Denne delen hopper mange over når de har lest mange artikler på dette området. Likevel kan det være hensiktsmessig å lese introduksjonen om det er fagområder du har begrenset kjennskap til.
Metode
I metodekapittelet blir du kjent med hvordan studien ble gjennomført. Det vil si inklusjons- og eksklusjonskriterier, treningsprogram om de benyttet det, informasjon om deltakerne i studien og hvilke måleinstrumenter som ble brukt. Protokollen skal være så tydelig og presis at du skal være i stand til å gjennomføre studien på nytt. Dette kapitelet forteller deg om generaliserbarheten til studien. Hvem gjelder egentlig resultatene for? Er studien gjennomført på utrente menn mellom 45 og 70 år vil ikke resultatene være like gjeldende for en godt trent dame på 28 år. Disse punktene er viktig når du skal anvende resultatene i praksis. Du bør også få en detaljert oversikt over treningsprogrammet som er benyttet i studien. Det forteller deg mye om den økologiske validiteten. Kort fortalt forteller den økologiske validiteten om hvor generaliserbar studien er til den virkelige verden. Legg også merke til hvilket utstyr de bruker. Har utstyret blitt brukt før? Hvor nøyaktig er det? Eksempelvis vil en dexa-scan være mer nøyaktig enn en Inbody 720, som ofte brukes på treningssentre for måling av fettfrimasse. Metodekapittelet ender som regel med en statistikkseksjon. Her viser forfatterne hvilken statistikk de har benyttet. Her kan du møte på en rekke fremmed ord. Eksempler på dette er mean, standard deviation, P-value, R-value, T-test, ANOVA, within-group, between-group, post-Hoc og effect size. Dette er bare en brøkdel av ordene du kan møte på. Stian har dekket dette i sin artikkel som du finner her .
Resultat
Om du ikke er så glad i tall kan dette være et veldig utfordrende kapittel i artikkelen. Jeg har lagt inn noen eksempler under på hva de forskjellige tallene og tegnene betyr på noen utvalget figurer. Det du bør se etter i dette kapittelet er eksakte resultater på det du leter etter samt p verdien og effektstørrelsen. Se også etter main time effect, group effect og interaction effect.
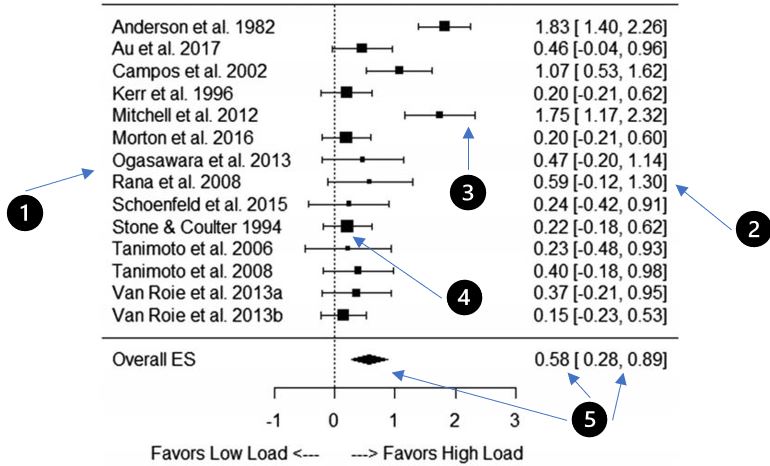
Figur 1 Forest plot hentet fra Schoenfeld et al,.2017
På figur 1 ser vi et forest plot. Dette brukes mye i meta-analyser når en skal sammenligne resultater fra flere studier som har sett på det samme.
-
- Punkt 1 er en liste over alle studiene som er inkludert i forest plottet.
- - Punkt 2 viser effektstørrelsen og konfidensintervallet til hver enkelt studie oppgitt med eksakte verdier. For detaljer om effektstørrelse følg denne lenken.
- - Punkt 3 viser konfidensintervallet. Veldig enkelt forklart så kan en bruke konfidensintervallet til å se hvor konsistente dataene er. En kan også si at konfidensintervallet er utvalget av verdier der du kan være 95% sikker på at den sanne verdien ligger. Størrelsen på studien påvirker også lengden (størrelsen) på konfidensintervallet. Store studier har ofte små konfidensintervall og motsatt.
- - Punkt 4 viser en svart boks. Størrelsen på boksen viser hvor mange deltakere det var i studien. En større boks betyr flere deltakere.
- - Punkt 5 viser samlet resultat for alle studiene. Det vi ser i dette eksempelet er effektstørrelsen og konfidensintervallet. Når det svarte feltet er på høyre side av den stiplede linjen (0-punktet) og ikke krysser den er fordelen til high load statistisk signifikant. I de aller fleste forest plot så er det dette konfidensintervallet som er det smaleste[SL1] / minste. Vi ser at konfidensintervallet ikke krysser 0 her. Da er vi 95 prosent sikkert på at den eksakte verdien for alle studiene lagt sammen ikke er 0.
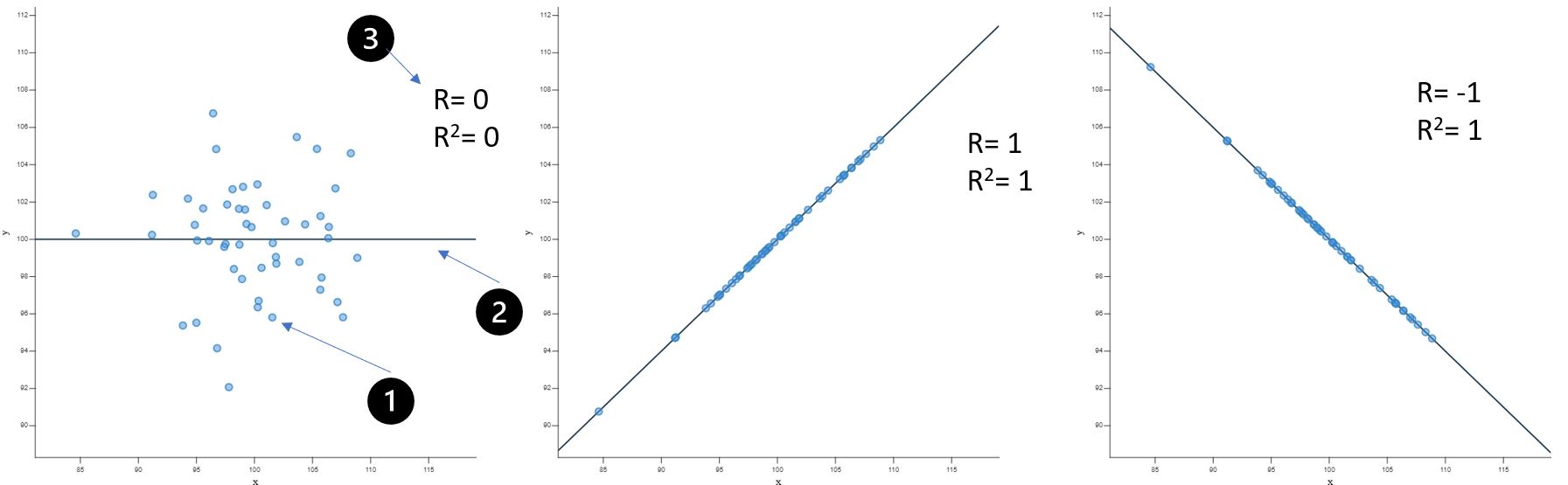
Figur 2 Korrelasjonsplot som er laget med https://rpsychologist.com/correlation/
Hvordan og hvorfor er FFM gjeldende innenfor autoregulering?
På figur 2 ser vi 3 forskjellige korrelasjonsplot. Korrelasjon er sammenhengen mellom 2 variabler. Helt til venstre så ser vi et eksempel på ingen korrelasjon. Figuren i midten har en perfekt positiv korrelasjon, og figuren til venstre har en perfekt negativ korrelasjon. Verdiene kan gå fra -1 til 1 i et korrelasjonsplot. At korrelasjonen er negativ, betyr ikke automatisk et dårlig resultat. Det betyr at når verdien øker på x-aksen så synker den på y-aksen. Eksempel på hvor en kan oppnå en negativ korrelasjon er om en ser på sammenhengen mellom hopphøyde og sprinttid. Både spenst og hurtighet bygger på eksplosive ferdigheter og en kan tenke seg at en hurtig person også kan hoppe høyt. I en hurtighetstest ønsker du lavest mulig verdi (9 sekunder på 100 meter er bedre enn 10 sekunder) og i en spensttest ønsker du høyest mulig verdi (2,5 meter er bedre enn 2 meter). Derfor vil sammenhengen her gå nedover siden en eksplosiv person mest sannsynlig får en lav verdi på hurtighetstest og en høy verdi på spenstesten.
-
- Punkt 1 viser individuelle data fra x og y-aksen. Hvert punkt en unik person sitt resultat.
- - Punkt 2 viser en trendlinje. Den gir deg et tegn på hvor sterk eller svak en korrelasjon er.
- - Punkt 3 er korrelasjonsverdiene. R= xx viser hvor sterk korrelasjon det er mellom to variabler og R2= xx viser hvor mye den ene variabelen kan forklare variansen av den andre variabelen.
Om du vil leke litt med korrelasjonsplot for en økt forståelse så anbefaler jeg denne siden her.
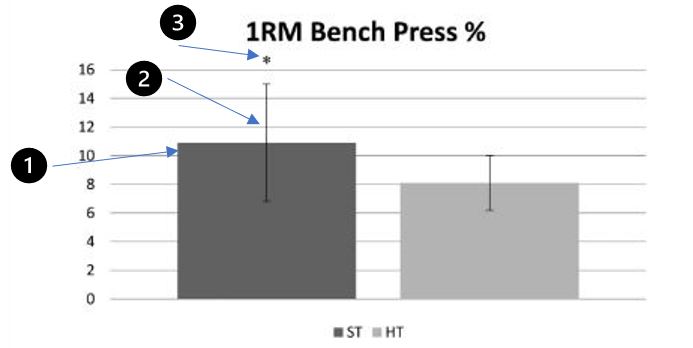
Figur 3 Søylediagram hentet fra Schoenfeld et al,. 2015
På figur 3 ser vi et søylediagram. Dette viser en forskjell mellom to grupper når det kommer til prosentvis økning i benkpress. I dette tilfelle så viser det between-group forskjeller, altså mellom gruppene.
-
- Punkt 1 (søylediagrammet) viser gjennomsnittet i gruppen (mean/aritmetisk gjennomsnitt).
-
- Punkt 2 er standardavviket. Standardavviket viser variansen i gruppen. Et stort (lang strek) standardavvik tyder på mye varians i data. Dette får en ofte om en har heterogene grupper kontra homogene grupper. Tester du benkpress på en gruppe styrkeløftere på høyt nivå (samme vektklasse) så vil mest sannsynlig standardavviket være lite. Årsaken er at dette er en homogen gruppe hvor utøverne kan forventes å ha lignede karakteristikker. Tester en derimot benkpress på et tilfeldig utvalg med mennesker fra et treningssenter vil standardavviket mest sannsynlig være større. I det tilfeldige utvalget fra treningssenteret vil du kunne få noen som trener benkpress systematisk og noen som knapt har trent benkpress før. Dette er da en heterogen gruppe.
-
- Punkt 3 viser hvorvidt det er en statistisk signifikant forskjell mellom gruppene. I de fleste tilfeller benyttes det en stjerne/asterisk for å vise dette. En tommelfingerregler når du leser artikler om trening og er ernæring er at en stjerne betyr signifikant på p < 0.05 nivå, to stjerner betyr signifikant på p < 0.01 nivå, og tre stjerner betyr signifikant på p < 0.001 nivå.
Diskusjon
Dette er den avsluttende delen av artikkelen. Her skal en oppsummere funnene og diskutere dette opp mot annen forskning. Fant de noe annet enn tidligere forskning? Om ja, hvorfor? Videre så skal en se på begrensningene til studien samt komme med forslag til videre forskning på området. Denne delen avsluttes ofte med konklusjoner og praktiske tips til bruksområder for studien.
Typiske forkortelser
De fleste forkortelser blir forklart første gang de blir brukt, men noen er så vanlig at de ikke blir forklart.
-
N = antall deltakere i studien eller i gruppen. Om det står n = 8 betyr det at det er 8 i den studien eller gruppen.
-
SD = standard deviation. Dette er et mål på variansen i datasettet.
-
RT = resistance training. Styrketrening i tradisjonell form.
- MT = muscle thickness. Et mål på muskelstørrelse.
- CSA= cross sectional area. Et mål på muskelstørrelse
- MRI = magnetic resonance imaging. Apparat for måling av muskelstørrelse.
- ES = effect size. Forkortelse for effektstørrelse.
- CI = confidence interval. Forkortelse for konfidensintervall
- P = probability. Sjansen for at resultatet er funnet på bakgrunn av en tilfeldighet. P = 0.03 betyr at det er 3 % sjanse for at resultatet er funnet på bakgrunn av en tilfeldighet. Forenklet versjon av p verdi.
- LBM = Lean body mass. Fettfrimasse, kroppsvekt minus fett. OBS! LBM er mer enn bare muskelmasse.
- Pre og post test = Tester som er gjort før eller etter en behandeling. Behandlingen kan være kosttilskudd, en treningsform eller endringer i dietten. Her ser en på effekten av behandlingen. Hvor stor er endringen fra før behandling til etter behandling.
- Within – group = hvordan var endringene eller forskjellen innad i en gruppe.
- Between – group = hvordan var endringene eller forskjellen mellom gruppene.
Studier som er inkludert i artikkelen
- Schoenfeld, B., Grgic, J., Ogborn, D., & Krieger, J. (2017). Strength and hypertrophy adaptatons between low- vs. high-load resistance training: a systematic review and meta-analysis. Journal of Strength and Conditioning Research. doi: 10.1519/JSC.0000000000002200
- Schoenfeld, B., Peterson, M., Ogborn, D., Contreras, B., & Sonmez, G. (2015). Effects of low- vs. high-load resistance training on muscle hypertrophy in well-trained men. The Journal of Strength and Conditioning Research. doi: 10.1519/JSC.0000000000000958
Om forfatteren
Markus Haugen

.png) Norsk
Norsk.png) English
English